
最近越来越多公司、团队,甚至个体,都在聊 RPA 但坦率地讲,我自己看下来,很多人对 RPA 的理解,还是有点停留在表面
一提到 RPA,脑子里想到的就是, 录个流程,抓抓元素,点点按钮, 让机器人替人干活, 然后效率提升,皆大欢喜
这当然没错 但如果你真的下场做过一个完整的 RPA 项目,你很快就会发现,真正麻烦的,从来不是“写脚本”这一步
真正决定一个 RPA 项目能不能活下来的,往往是后面这些事: 需求有没有梳理清楚? 流程到底适不适合自动化? 异常怎么兜底? 上线之后谁来维护?业务还是开发? 系统一改版怎么办, 业务一变动怎么办, 做出来之后到底有没有人持续在用?
也就是说,RPA 不是一个“写完就结束”的工具活 它更像一个完整的小型产品项目
如果你把它当脚本来做,大概率会反复返工 如果你把它当业务系统的一部分来做,很多动作一开始就会不一样
所以这篇我不想只聊技术细节 我更想把 RPA 的全流程开发,按一个更真实的视角,完整讲一遍
从需求梳理,到流程设计,到开发测试,再到上线维护 如果你刚好准备做 RPA,或者已经做过几个但总感觉项目一上线就开始乱,这篇应该会对你有帮助
流程能不能做,比怎么做更重要
先说一个最容易被忽略的点
不是所有流程,都值得做 RPA
这句话听起来像废话,但现实里真有很多项目,一开始就死在这里
业务同学说,这个流程很烦,能不能自动化一下 老板说,这个岗位的任务每天都在重复劳动,做个机器人吧 开发说,好,先做一个看看
结果做着做着发现, 流程本身天天变, 规则不稳定, 中间很多判断靠人拍板, 上游数据质量又差, 最后机器人不是在工作,是在不停报错
这种项目不是技术不行, 是流程压根就不适合直接自动化
所以一个成熟的 RPA 项目,第一步绝对不是开开发工具脚本 第一步是判断,这个需求值不值得做
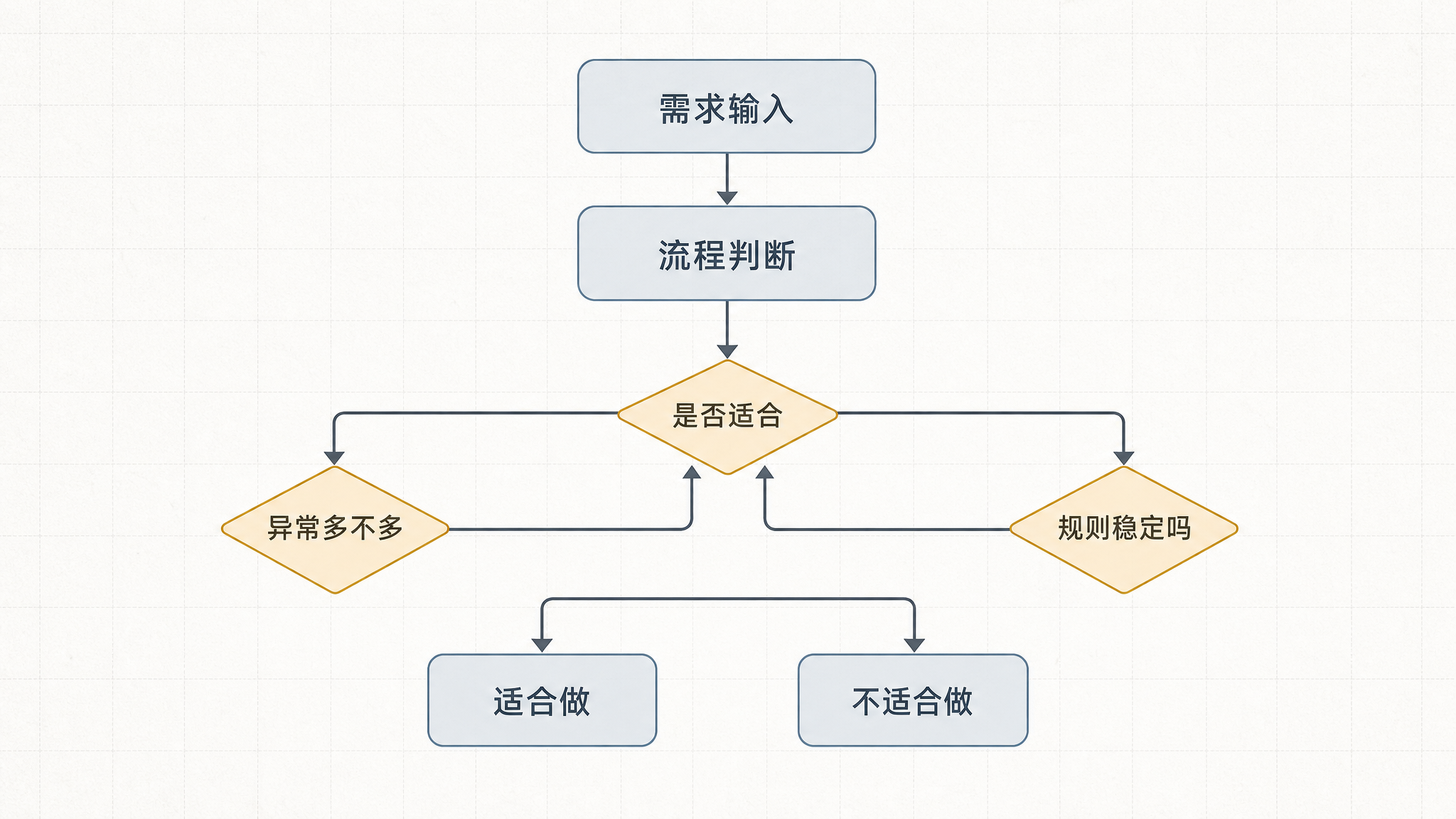
我一般会先看四件事
第一,这个流程是不是高频重复 如果一个月就跑一次,而且一次只省十分钟,那你大概率不该优先做它
第二,规则是不是相对稳定 RPA 最怕的不是复杂,而是今天这样、明天那样,规则永远在漂
第三,输入输出能不能相对标准化 如果上游数据今天 Excel、明天截图、后天语音转文字,那维护成本会非常难看
第四,异常比例高不高 如果这个流程 30% 都要人工介入,那它更像一个半自动辅助流程,不是纯自动流程
说白了,RPA 最擅长的,不是“复杂但聪明”的活 它最擅长的是“规则明确但烦人”的活
这个边界一旦搞错,后面基本都在补锅
需求判断过了,下一步才是需求梳理
很多人做 RPA,一上来就问, 你想自动化什么步骤, 你现在点哪些按钮, 账号密码给我一下
这不算错,但太快了
因为业务描述的,往往只是“表面动作”,不是“真实流程”
比如业务会说, 我们每天要把订单从系统 A 导出来,再录到系统 B 里
你一听,觉得挺适合 RPA 但你真往下问,会问出一堆东西
哪些订单要导 不同类型订单规则一样吗 有没有金额阈值 有没有黑名单客户 导入失败后怎么处理 系统 B 录完之后要不要回写状态 如果当天数据缺字段,是先跳过还是先挂起? 谁来确认最终结果?
你会发现,表面上是“搬数据”,实际上里面藏着很多业务判断
所以需求梳理这一步,最重要的不是记按钮路径 而是把整个业务逻辑掰开
我一般建议至少梳理出下面这些东西
先把流程边界定清楚 机器人到底从哪里开始,到哪里结束 哪些环节归它,哪些环节必须人工做
再把触发条件定清楚 是定时跑,还是人工触发,还是收到某种文件后触发
然后把输入输出列清楚 输入是什么格式,来自哪里 输出要落到哪里,要生成什么结果,要通知谁
接着把业务规则一条条列出来 哪些是固定规则,哪些是例外规则,哪些是待确认规则
最后把异常场景单独拉出来 登录失败怎么办 页面元素找不到怎么办 数据为空怎么办 接口超时怎么办 碰到脏数据怎么办
这一步做得越细,后面开发越轻松 反过来说,很多 RPA 项目后面疯狂返工,根本原因不是代码差,而是前面把模糊需求硬做成了脚本 导致很多项目从一开始就积累了很多技术债,后面又接上新的开发任务,然后恶性循环
到这里,流程图就该出来了
而且最好不是那种只给领导看的漂亮流程图 而是真能指导开发的那种
也就是你要把正常流程、分支流程、异常流程都画出来 哪些节点是判断,哪些节点是人工确认,哪些节点是外部系统依赖,要清清楚楚
因为 RPA 最怕脑补 你不把流程画清楚,开发时就只能一边写一边猜 而一旦靠猜,后面出问题几乎是必然的
需求和流程梳理完,才进入方案设计
这一步很多人也容易轻视,觉得 RPA 不就是拖几个组件、写几个循环判断吗,还要设计什么
但说实话,真做项目的时候,设计做得好不好,直接决定你后面维护会不会痛苦
这里至少要想四件事
第一,技术路线怎么选 你是纯 UI 自动化,还是尽量走接口 是桌面端自动化,网页端自动化,还是混合模式 如果有 API 能直接打,通常都比纯界面点击更稳 RPA 能点页面,不代表你就该点页面
第二,流程颗粒度怎么拆 是做成一个大流程一口气跑完,还是拆成多个子流程 我自己的经验是,只要流程稍微复杂一点,就尽量模块化 登录一个模块,数据清洗一个模块,业务处理一个模块,结果通知一个模块 这样后面改起来真的省很多事
第三,数据和配置怎么管理 哪些参数写死,哪些放配置文件 不同环境的地址、账号、阈值、文件路径,要不要可配置 如果这一步偷懒,后面每次改一点小参数都得重新发版
第四,日志和监控怎么做 很多人开发时只想着“跑通” 但真正上线后,你最想看的不是机器人能不能跑,而是它到底跑到了哪一步,为什么失败,失败后影响了多少数据
所以一个能长期跑的 RPA,日志绝对不能敷衍 至少要能回答这几个问题: 什么时候开始跑的, 处理了多少条, 成功多少条, 失败多少条, 失败在哪一步, 错误信息是什么, 有没有重试, 有没有录屏回放, 最终通知给谁了
这玩意平时看着不起眼,真出故障时就是救命绳
跑通一次很容易,稳定跑下去很难
设计之后才是开发
开发阶段最容易犯的错误,是只追求“本地跑通”
本地跑通当然重要,但它只是最低标准
你真正该追求的是, 流程稳定, 异常可控, 结果可核对, 别人接手也能看懂
所以我觉得 RPA 开发时,至少要守住几个原则
不要把所有逻辑都塞在一个流程里 不要把所有判断都写成一长串嵌套 不要把关键规则散落在十几个节点备注里 不要只在报错时弹一个“执行失败”就结束
最好把核心业务规则抽出来 把关键输入做校验 把外部依赖调用包上重试和超时控制 把关键节点都留日志 把中间结果尽量可追溯
还有一个很现实的坑
页面自动化真的很脆弱
按钮文案一改,挂 元素层级一变,挂 页面加载慢一点,挂 系统风控制裁,挂 分辨率不一致,挂 浏览器升级,挂
所以只要是 UI 自动化,开发时就要默认它未来会坏 别按“永远稳定”来写,要按“迟早变化”来设计
这也是为什么我一直觉得,RPA 工程师如果只会拖拽流程,其实不够 你得有一点工程意识 知道怎么做容错,怎么拆模块,怎么写日志,怎么做配置,怎么留维护空间
不然你做出来的不是自动化资产,是一个脆皮脚本
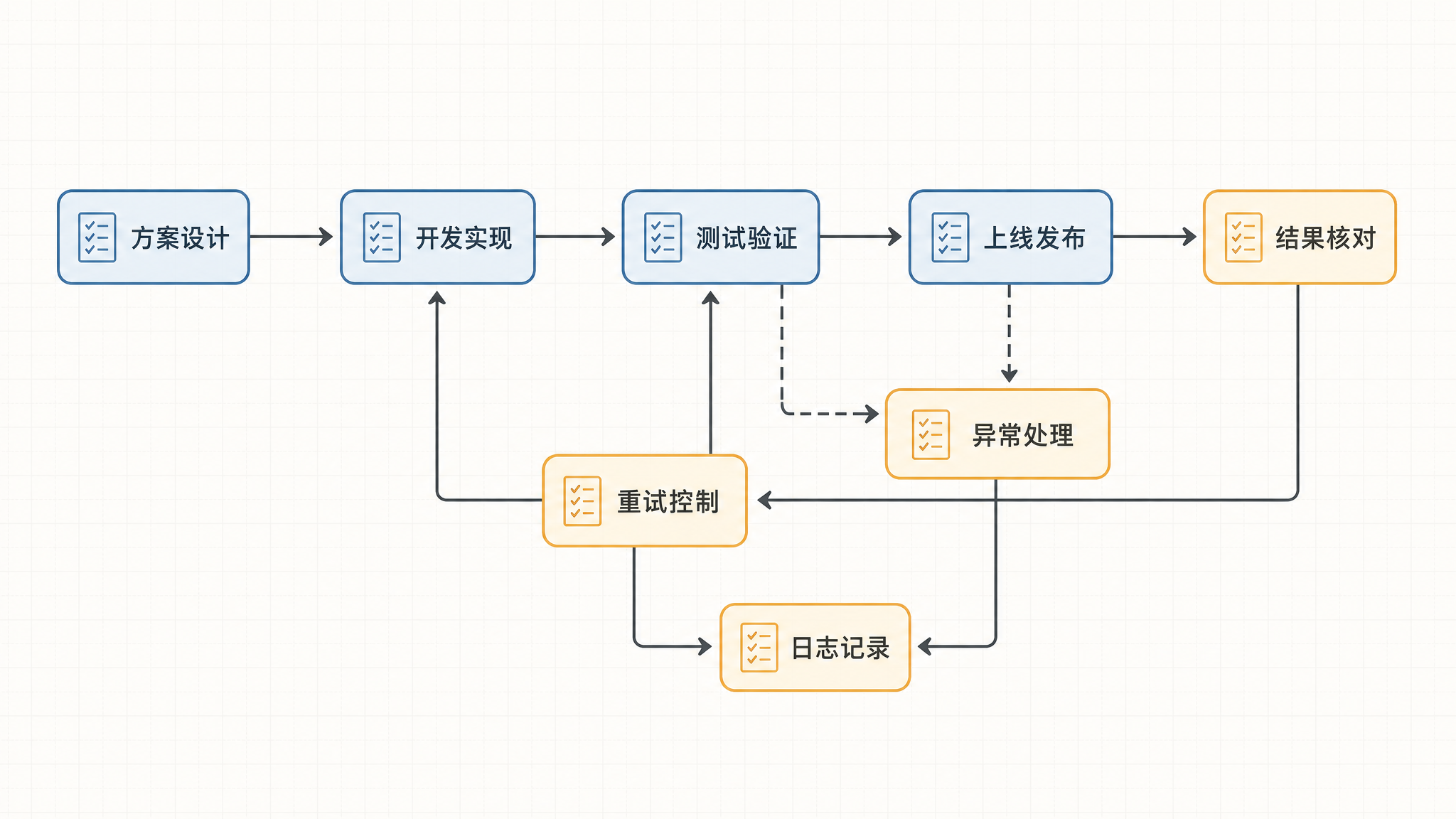
开发完之后,不是直接上线 中间还有一个经常被赶工压缩,但其实非常关键的阶段,就是测试
RPA 的测试,不能只测“能不能跑完”
你至少得测三层
第一层,正常路径 标准输入下,能不能稳定跑完,结果对不对
第二层,边界情况 空数据、重复数据、缺字段、超长文本、特殊字符,这些会不会出问题
第三层,异常场景 网络断了怎么办 登录验证码弹出来怎么办 目标系统响应慢怎么办 写入一半失败怎么办
很多 RPA 一上线就翻车,不是因为主流程没写好 而是因为大家默认现实世界会很配合
但现实世界最不配合
测试时还有一个特别重要的动作,就是让业务一起验收
因为开发眼里的“跑通”,不一定等于业务眼里的“可用”
开发可能觉得, 数据成功录进去了,任务完成
但业务会说, 不对,我们还要看回执文件, 还要校验某个状态位, 还要给下游发一封确认邮件
所以验收标准最好前置 别等上线前一天才问“你们到底想要什么结果”
测试过了,才进入上线
很多人以为上线就是把流程发到生产,设个定时器,结束
其实真正负责任的做法,至少还要补几件事
先做环境确认 生产环境账号、权限、文件路径、浏览器版本、目标系统地址,这些都要逐项核对
再做回滚预案 如果上线后失败,能不能快速切回人工流程 最怕的是机器人没跑成,人工流程也来不及补
然后做运行窗口管理 机器人什么时候跑,避不避开业务高峰,和别的系统任务会不会冲突,这些都得提前想
最后是通知机制 成功通知谁,失败通知谁,通知内容里要不要带任务编号、失败原因、日志链接
别小看这些运营动作 一个 RPA 能不能真正接进业务,无感知的融入业务中,可不只看开发质量
上线只是起点,后面的维护才是长跑
上线之后,很多新手开发就开始松懈了,觉得项目交付完了
但说实话,RPA 真正的工作,往往是从上线后才开始的,上线之后才是维护和迭代的开始
因为它不是一个静止环境里的程序 它一直活在变化里
业务规则会变 上游模板会变 目标系统页面会变 后台接口会变 账号权限会变 浏览器和驱动会变 甚至做这个流程的人都会变
所以维护不是补充项,而是 RPA 生命周期的一部分
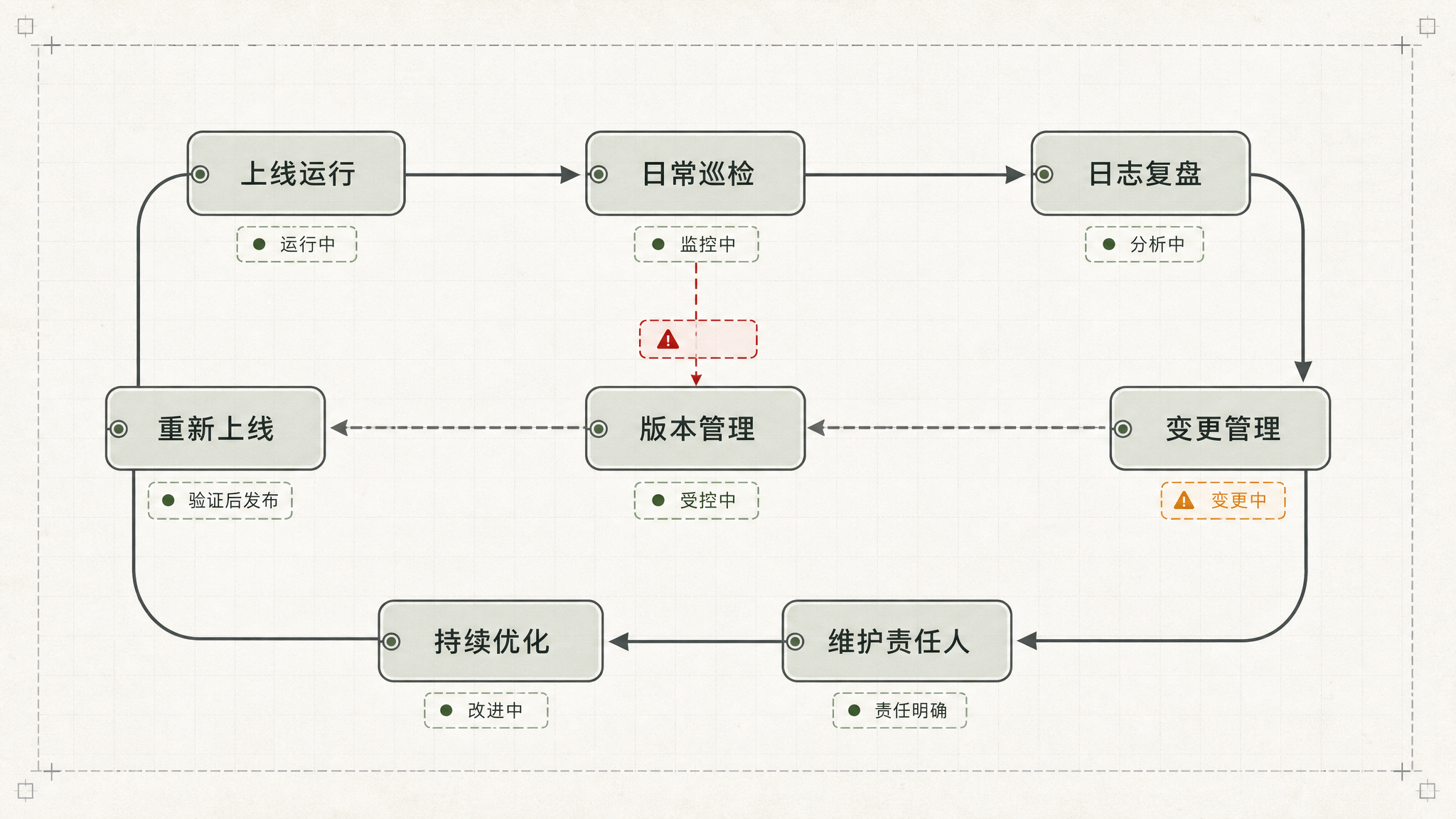
一个成熟的维护体系,我觉得至少要有这几层
第一,日常巡检 不是等报错了才看,而是定期检查成功率、失败率、平均耗时、异常分布
第二,日志复盘 失败是偶发,还是集中在某一步 是数据问题,系统问题,还是流程设计问题 要能从日志和录屏中看出来
第三,变更管理 业务一改规则,不能口头说一声就完了 最好有明确的变更记录,谁提的,改了什么,什么时候上,做好责任归属
第四,版本管理 别让生产上跑着一个 nobody knows 的版本 至少要知道当前版本号、更新内容、回退方式,能git的git,能云端的云端
第五,维护责任人 这件事到底谁盯 业务报错后找谁 紧急情况谁处理 很多项目不是死于技术,而是死于“没人负责”,业务和开发互相甩
如果再往深一点看,RPA 做久了,你会发现一个更大的问题
很多团队把 RPA 当终点 但它很多时候,其实只是过渡方案
什么意思
如果一个流程长期高频、业务价值高、维护又重,那你就得开始想: 这件事未来是不是该接口化,能不能对接官方接口,抬高稳定性? 是不是该系统改造,合并老旧系统? 是不是该让上游直接规范数据, 是不是该从根上重构,而不是一直靠机器人搬运
RPA 最大的价值之一,是它能快速补上流程断层 但它不一定适合永远背着所有历史包袱往前跑
所以一个成熟团队,不只是会做 RPA 还会定期判断,这个流程还该不该继续用 RPA RPA——》agent,就是未来趋势
这点很重要
因为很多自动化项目,一开始是救火 后来却变成了新的历史债务
回到整条链路,我自己越来越觉得,RPA 全流程开发,难的从来不是“让机器人会点鼠标”
而是你能不能像做一个小型业务产品那样,认真对待它
从需求阶段就判断值不值得做 从梳理阶段就把规则和异常掰清楚 从设计阶段就考虑模块化、配置化、日志化 从开发阶段就预留维护空间 从测试阶段就把现实世界的脏乱差放进来 从上线阶段就把责任、通知、回滚安排好 从维护阶段就默认一切都会变
这样做出来的 RPA,才不是一次性交付物 它才更像一个能持续创造价值的自动化资产
如果你非要我把这件事压成一句话,我会这么说
RPA 不难做 难的是把 RPA 做成一个能活下去的系统
很多人卡在“开发机器人”这一步 但真正拉开差距的,是谁能把后面的需求、测试、上线、维护,一起想明白
这也是为什么我现在越来越不太喜欢把 RPA 说成“自动点点点”
它当然可以很轻 但一旦你真想让它稳定接进业务,它就一定不只是点点点那么简单
它背后其实是一整套对流程、系统、异常、责任和维护的理解 是无声无息的融入业务的日常工作中 是省去重复时间换来的价值更替
而这部分,才是真正属于RPA价值的地方
