
国内外电商平台数据连接器
从天猫、千牛、京东、拼多多、唯品会、亚马逊、TikTok 等平台抓取订单、商品与经营数据,统一入库,并同步到飞书多维表格,服务后续分析、协同和自动化处理
项目概览
这个项目的是多平台、多店铺、多取数路径的聚合取数系统,本文章讲概括阐述如何搭建一套能够长期运行的数据连接系统
在真实业务里,不同电商平台会提供不同类型的数据对象,例如订单表、推广数据表、商品表、库存表、经营报表等。即使同样是订单数据,不同平台的字段结构、状态定义、时间口径、报表入口和开放能力也并不一致。进一步拆开看,同一平台下往往存在多家店铺,而同一家店铺内部又可能存在多条不同的取数路径,例如官方 API、后台报表导出、页面列表抓取或固定人工操作流程自动化
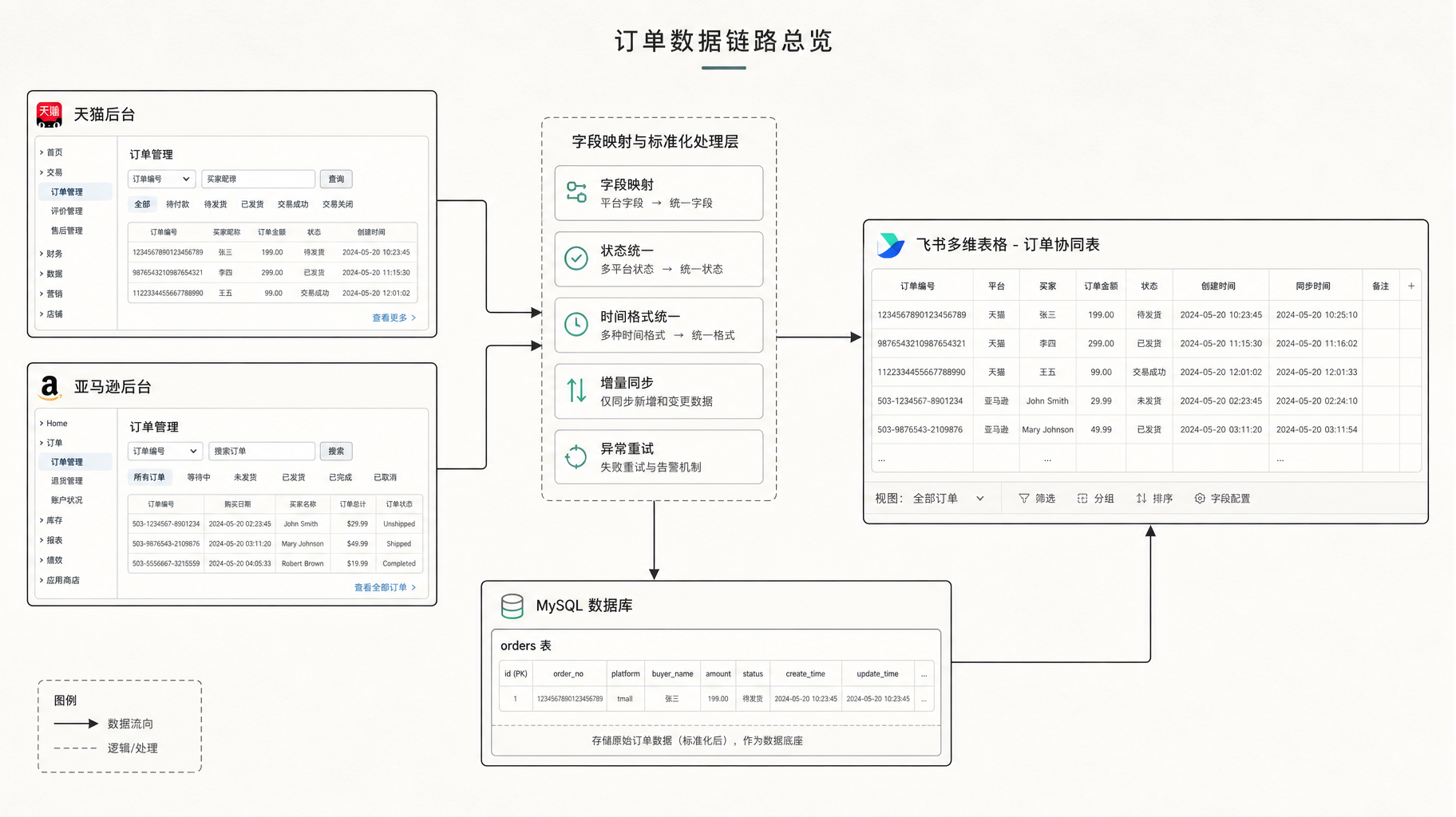
设计思路
这套连接器采用的是分层式设计
整体思路可以概括为四个原则:
-
以平台为数据源,以店铺为业务单元
-
以官方 API 为优先取数方式,以 RPA 为补充取数方式
-
以统一数据模型为入库标准,而不是直接落平台原始结构
-
以数据库为标准底座,以飞书多维表格为业务结果层
-
API 取数和 RPA 取数是分开的,两者承担的职责不同
-
官方 API 优先用于结构化字段同步、稳定增量取数和长期维护
-
RPA 主要用于平台开放不足、字段覆盖不足或业务必须依赖后台报表导出的场景
也就是说,RPA 不是默认方案,而是次选方案。只有当 API 无法覆盖目标数据对象,或者无法满足业务需要时,才通过影刀 RPA 模拟人工进入后台、执行报表导出或页面取数,再进入后续入库流程。
数据源结构
从数据源视角看,这个项目需要同时处理三层差异:
-
平台差异
不同平台具备不同的数据对象和后台结构,例如订单表、推广数据表、商品数据表的入口和字段设计都不同 -
店铺差异
同一平台下的不同店铺,可能对应不同权限、不同报表范围、不同业务线和不同同步频率 -
取数路径差异
同一店铺下,不同数据对象可能对应不同取数方式,例如订单数据走 API,推广报表走后台导出,经营报表走固定页面流程
系统中有一层明确的任务配置和来源管理逻辑:
- 当前数据属于哪个平台
- 当前数据属于哪个店铺
- 当前数据对象是什么
- 当前任务走 API 还是 RPA
- 当前同步时间窗口和同步频率是什么
接入层是整套系统的第一层,它的职责是把各个平台、各家店铺的不同数据入口,统一抽象成可调度的数据采集任务。
这一层内部并不把 API 和 RPA 混在一起,而是明确拆成两类 adapter。
API Adapter
API Adapter 负责:
- 调用官方接口获取结构化数据
- 处理认证、分页、限流和时间窗口
- 按平台返回格式解析原始字段
- 作为稳定字段和高频同步的优先路径
对于能由 API 覆盖的数据对象,优先选择 API,是因为这类方式更容易做增量同步、失败重试和长期维护
RPA Adapter
RPA Adapter 负责:
- 进入后台页面执行固定操作流程
- 根据条件筛选数据范围
- 下载平台报表或抓取页面列表数据
- 承接平台未开放或 API 不足覆盖的数据对象
在这类项目里,RPA 更接近“模拟人工完成后台数据导出”。它承担的是平台开放能力不足时的取数补位职责
以天猫订单表说明接入逻辑
这篇文章虽然讲的是多平台项目,但为了让结构更具体,可以用天猫订单表来说明单条链路是如何进入系统的。
在天猫场景下,订单数据通常有两类来源:
- 能由官方 API 稳定导出覆盖的结构化订单数据
- 需要RPA通过后台订单列表、订单详情页或报表导出订单数据
一般优先级是:
- 优先使用 API 获取稳定主字段
- 当 API 覆盖不足时,补充 RPA 任务进入后台导出或抓取
- 两类结果进入统一原始数据层,再进入标准化和入库流程
从字段层面看,一次订单同步可能关注:
- 平台订单号
- 店铺名
- 商品标题
- SKU 规格
- 订单状态
- 实付金额
- 下单时间
- 发货时间
这里要强调的是,天猫订单表只是一个解释项目逻辑的例子。实际系统中,推广数据表、商品表和其他平台下的同类数据对象,都会走同样的分层链路,只是 adapter 和 mapping 规则不同。
原始数据层:先保留来源结果
连接器如果只保留清洗后的结果,后续维护会非常困难
因此,在接入层之后,系统会先进入原始数据层,用来保存或引用各类取数结果。这里承接的内容通常包括:
- API 返回的原始结构化结果
- RPA 导出的原始报表文件
- 页面抓取结果或详情页提取结果
- 当前同步任务对应的平台、店铺、时间窗口和批次信息
这一层的价值主要体现在:
- 字段变更时可以回查原始来源
- 任务失败时可以快速定位异常环节
- 标准化规则调整时可以重新处理原始结果
- 同一批次多次重跑时可以做结果核对
原始数据层是整套系统可追踪、可审计、可维护的基础
标准化层:把平台语言翻译成内部统一模型
平台取数完成之后,真正决定项目质量的,是标准化层
因为不同平台、不同店铺、不同数据对象的字段结构并不统一,所以系统不会直接把平台原始表落进数据库,而是先映射为内部统一模型。这个过程本质上是在做一层“平台语言到内部业务语言”的翻译
这一层主要处理:
- 字段命名统一
- 状态语义统一
- 时间格式统一
- 金额口径统一
- 平台扩展字段承接
以天猫订单表为例,映射过程可以理解为:
- 天猫原始订单号映射为
platform_order_id - 店铺名称映射为
shop_name - 页面状态或报表状态映射为统一
order_status - 平台时间字段统一写入标准时间列
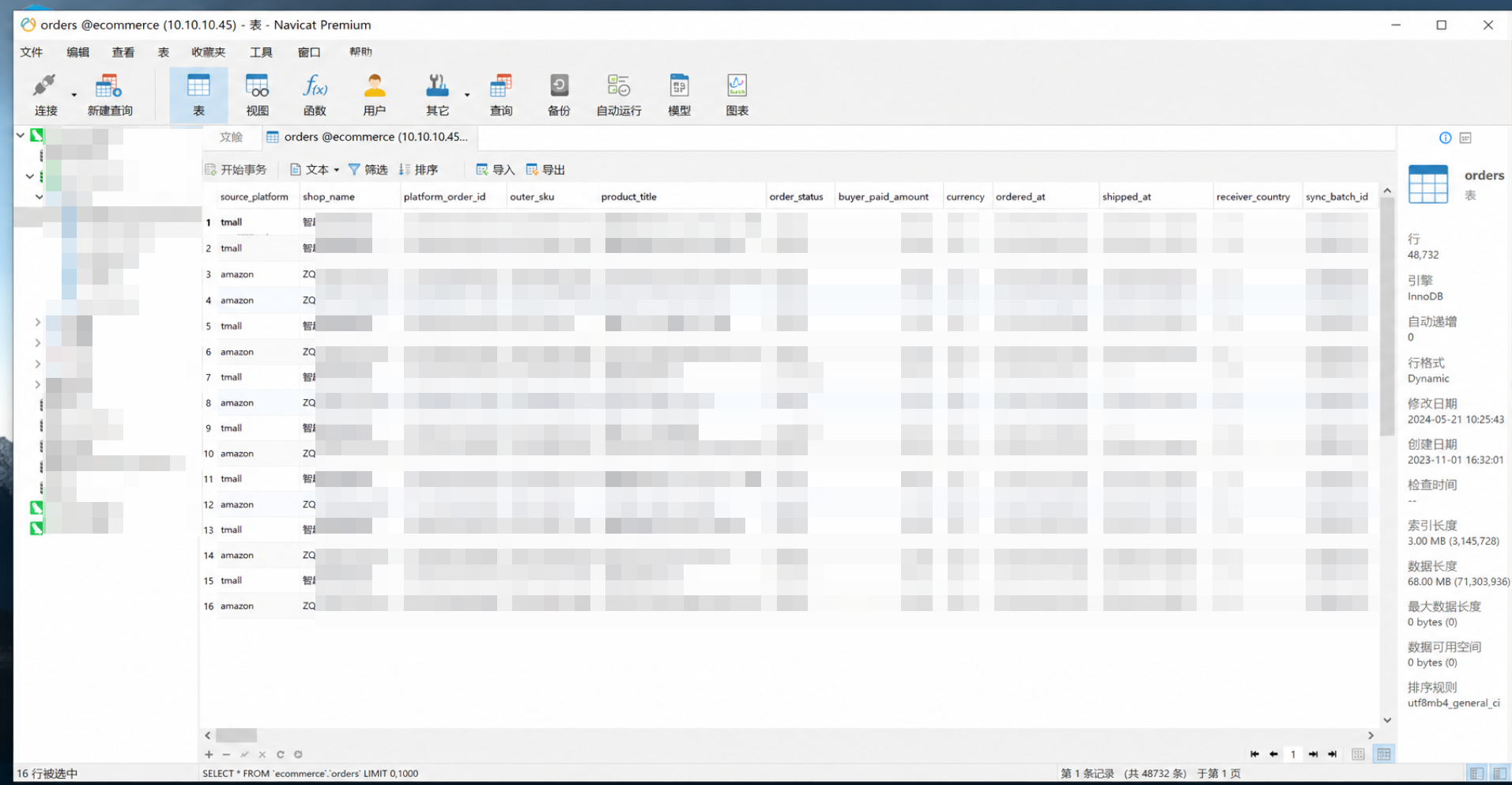
一个简化后的订单表示例可以长这样:
| 字段名 | 含义 | 来源示例 |
|---|---|---|
source_platform | 来源平台 | tmall |
shop_name | 店铺名 | 天猫旗舰店 |
platform_order_id | 平台订单号 | 平台原始订单号 |
outer_sku | 商家 SKU | 商品或规格编码 |
product_title | 商品标题 | 平台商品名称 |
order_status | 统一订单状态 | pending paid shipped closed |
buyer_paid_amount | 买家实付金额 | 平台付款金额 |
currency | 币种 | CNY |
ordered_at | 下单时间 | 标准时间格式 |
shipped_at | 发货时间 | 标准时间格式 |
receiver_country | 收货国家或地区 | CN |
sync_batch_id | 同步批次号 | 用于追踪本次任务 |
raw_payload_ref | 原始数据引用 | 留给排错和回查 |
同样的标准化思路,也会应用到其他平台的订单表、推广数据表和经营数据表上。区别只在于原始字段来源不同,但统一模型和处理流程是一致的
入库层:把标准结果写入数据库
标准化之后,数据会进入数据库层
这一层不是简单地“存一下结果”,而是要把多平台、多店铺、多路径的输出,统一写入可复用的标准底座中。对于订单类数据,MySQL 中至少会存在几类关键结构:
orders,承接标准订单明细sync_tasks,记录任务批次、平台、店铺、数据对象和时间窗口sync_logs,记录成功、失败、重试和异常信息raw_records或原始引用表,承接原始数据来源关联
数据库层承担的关键职责包括:
- 为不同平台和店铺的结果提供统一落点
- 保证历史数据可回溯
- 为报表、分析和自动化提供统一输入
- 为任务重跑、补同步和异常排查提供支撑
流程措施
为了保证长期可用,还需要保证日常维护,需要搭建一套流程管理系统 系统重点做了几类流程措施:
- 为每次同步生成批次号(唯一键值),区分不同平台、店铺、数据对象和时间窗口
- 在原始数据层保留来源结果,先转Execel文件再入库,便于追踪和回放
- 在入库前做统一字段映射和格式校验,避免平台原始结构直接污染标准表
- 记录同步日志、失败原因和重试结果,方便后续维护
对于 RPA 路径,还需要额外考虑:
- 页面结构变化后的节点维护
- 报表字段变化后的解析调整
- 导出失败或人工验证环节异常时的回退处理
这些流程措施的目的,是让连接器从“能取一次数据”,提升到“能持续运行并可追踪维护”
结果层:同步到飞书多维表格
数据库解决的是标准化沉淀问题,飞书多维表格解决的是业务协作问题
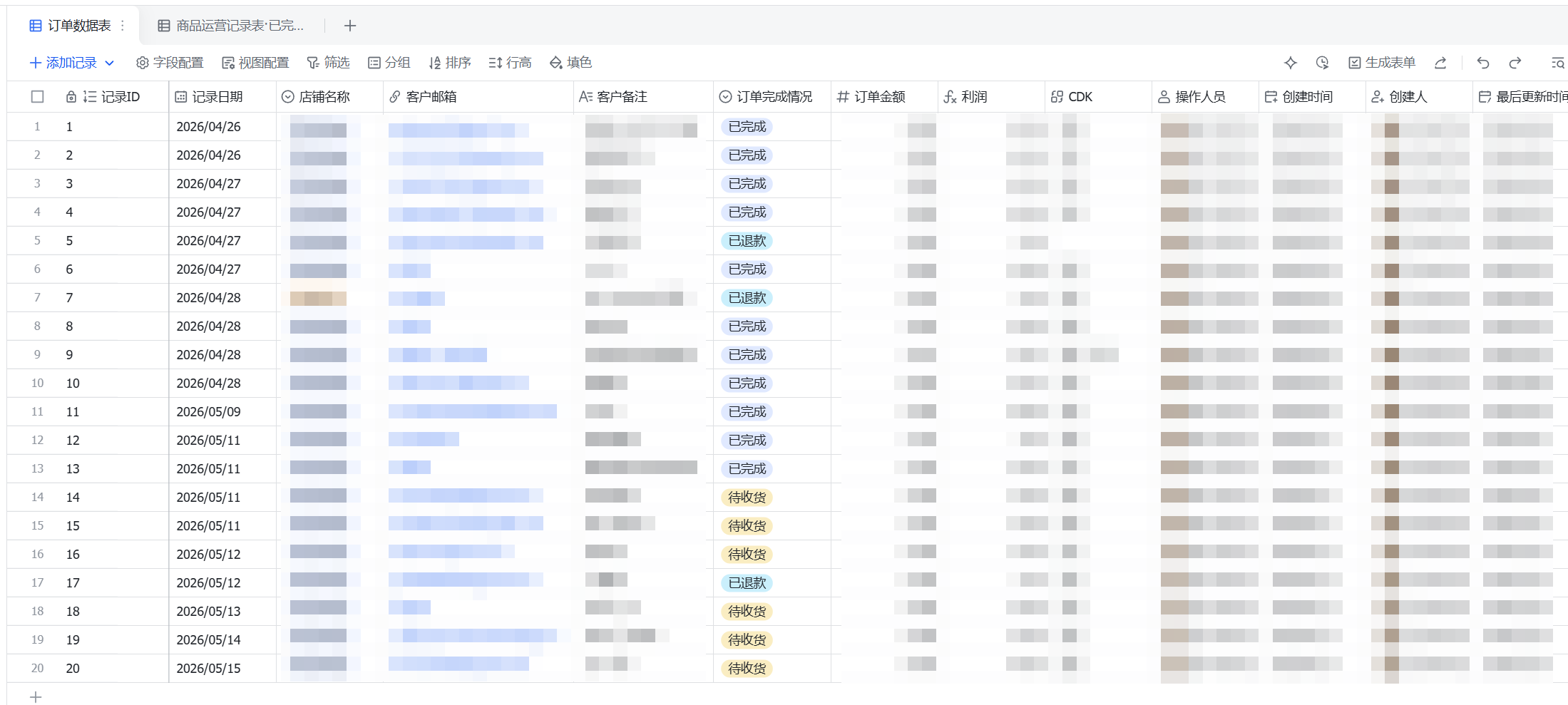
在实际使用中,业务团队通常不会直接操作 MySQL。他们更需要的是一张可以继续筛选、分配、标记异常和补充说明的结果表。因此,飞书同步层承担的是结果交付和协作承接职责